Thing I Made: CFWeaver
I made a simple CLI tool to generate comprehensive test scenarios from control flow models in simple markdown

Last week, I wrote about some thoughts I had related to test generation and control flow in business logic. This followed an effort at work that naturally turned out to be a good candidate for a model-based testing strategy. From this, I developed the tool CFWeaver to generate test scenarios from control flow models, which I've worked on over the last couple of weeks to get into a state that might be useful for others in a similar situation.
CFWeaver is a very simple CLI: you input a control flow model and it outputs test scenarios to exhaustively cover all the possible paths through the control flow. The input file is written in valid Markdown with a special syntax, and it's able to output either HTML or Markdown. You can read more about its function on its GitHub repository, but I'll give a small example here from the readme. I might have the following control flow model defined:
# Get an Item * Authenticate: Success | Failure = 403 ? I am not authenticated to access items* Validate: Success | Failure = 400 ? the request is invalid* GetFromDatabase: Found ? the item exists | Not found = 404 ? the item does not exist | Error = 500 ? The items table errors on select* Authorize: Success = 200 | Failure = 401 ? I am not authorized to access the specific itemCFWeaver can understand this model, compute the various combinations of control flow states, and generate the following (each row of the table being a test scenario):
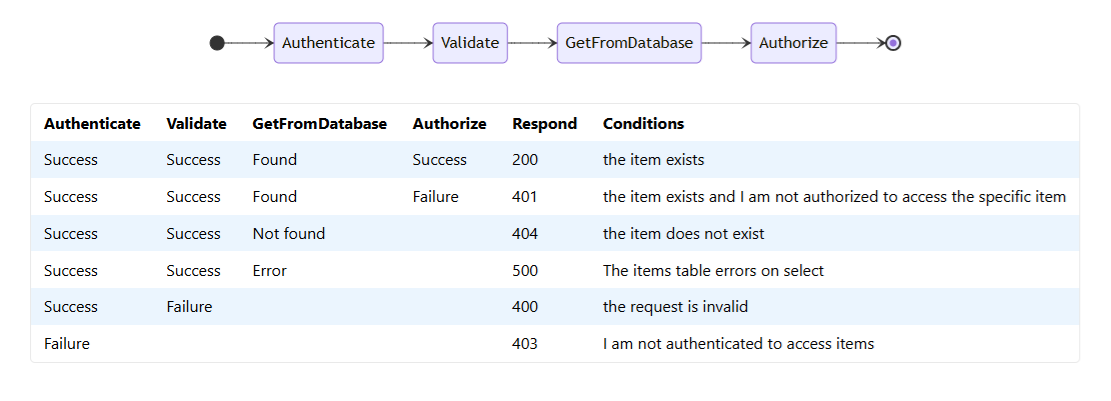
I've published CFWeaver at v0.9.0, with a small laundry list of tasks to get to "1.0" - I'll push some of those up to the repo as good first issues, if this project is interesting to you please do feel free to contribute!
This is far from a jack-of-all-trades though; I think there are some factors that constrain testing this way generally, and the utility of this tool specifically, which I think make the ideal use case for it a bit unique. There's not much to say about a simple CLI tool that can't be understood from its README, so below I'll elaborate a fair amount on my thoughts on using a model-based testing strategy in various scenarios.
Model-Based Testing #
The overarching concept here is model-based testing, which covers any number of approaches to test generation where some model of the system under test (SUT) is made, from which tests are generated. The model could be any number of things we normally use to model our software: a model of the input parameters, state diagrams, Markov chains, or in my case a control flow diagram. Some tools generate full test suites you can repeatedly run, some will randomly compute tests at the point of test execution, and others will stop short of generating the full test in favor of some description of the tests.
That latter behavior - only generating a description of the tests - is what CFWeaver does. Generating a full test suite which could be run directly against the SUT would have a few negative consequences. First, CFWeaver would almost certainly require much more fine-grained input about the nature of the SUT to be able to generate full, meaningful tests. This, in turn, raises the complexity and therefore development effort on my end. Finally, it would probably also restrict the types of systems for which CFWeaver could generate tests.
So, in order to maximize utility and ease development, CFWeaver only generates scenarios to test, with the conditions to cause the scenario and the expected result. This makes CFWeaver suitable to generate scenarios for any kind of system at any level of testing (unit, integration, e2e, and so forth), though there are natural constraints on when you'd want to employ a strategy like this.
On constraints, the most important consideration before employing any model-based strategy is the utility of the model from which the tests are generated. Since the tests aren't generated from the SUT itself, there needs to exist some model independent of that system. Does that separate model have a utility other than allowing tests to be generated from it? How difficult is it to develop that model? Does that model need to be maintained and evolved in tandem with the system in order to continue to be able to adequately test the system?
These are all important questions to ask. If the model has no use outside of being used to generate tests and is difficult to create and/or maintain, I'd suggest you have a poor candidate for model-based testing. Any practice, testing practices included, will not work well if they don't work harmoniously with your whole software process. If you naturally have models as a product of your process and the sorts of tests that can be generated from that model are useful for the sort of system you have, then you might want to consider a model-based testing strategy.
Take a web service, for example. I work on web services a lot these days. Often, services will generate an OpenAPI spec file as a result of their build processes. This model is easily generated, and it has a lot of utility in providing documentation to consumers, maybe generating clients, and so on. A tool like Schemathesis that randomly tests your service based on its OpenAPI spec might naturally fit into the workflow for a service with a good OpenAPI definition.
I developed CFWeaver from a similar position. I wrote a new service for my company, and the business logic of this service was based on what essentially amounted to control flow diagrams which had been collaborated on by various stakeholders. These models define the system and are maintained by the stakeholders independently of the system; when the system changes it will be as a result of some collaboration over these models. Being able to generate all the test scenarios from this model was greatly valuable in that I was able to verify the expected business requirements for the various technical faults that were possible.
Black or White Box Testing? #
Model-based testing supports both of these strategies, depending on how you come about your models. For review, black-box testing treats the SUT as a "black box" into which it cannot see; tests are based on external understandings of the system or the output from the system. White-box is the opposite; tests are based on information gleaned from the code of the system itself.
If I go into a codebase and read the code (or perform some other sort of static analysis) in order to come up with a model of a system, then I'm using model-based testing in a white-box manner. The project I described above that caused me to make CFWeaver is a black-box project; the model exists independently of the system, and the system is tested in a code-agnostic manner to ensure it conforms to that specification.
White-box approaches are good for testing technical aspects of the system and uncovering unexpected business requirements or lack thereof. For a web service, the return codes for various types of technical failures often fall under the purview of the business requirements for a system, and sometimes these scenarios can't be understood independently of the implementation of the system. Creating an independent model when analyzing a codebase for these sorts of technical states is usually beneficial, and a tool like CFWeaver can help after setting up the model if manually generating all the different scenarios is too complex or tedious.
Such an approach is (probably; usually) a one-time spelunking, and the model is probably discarded after the analysis and test scenario generation. However, it is a natural product of the analysis and useful for engineers collaborating while understanding a system. That's particularly useful when analyzing legacy (or otherwise poorly-understood) code.
I'm generally of the opinion though that the great majority of business logic can - and should - be tested from a black box approach. The software doesn't exist on its own, it exists because of an external requirement for its specific function. I largely don't care about implementation when it comes to ensuring the system meets those independent requirements, and on top of that it's beneficial to keep tests decoupled from implementation so that I can refactor the SUT without having to touch the tests; this makes refactoring easy and best ensures the success of the refactor (or any sort of change to the code, for that matter: feature add, bug fix, and so on).
I do not know, but if you asked me to guess I would say that model-based testing probably is less naturally suited to black-box testing because it's more rare that formal models exist independently of the SUT. Indeed, the OpenAPI spec example is probably the most ubiquitous one, and I luckily landed in a project for which I was able to formalize the independent model. Rarity aside, if the stars do happen to align in a way that a project does maintain models independently of the system, then a model-based approach can be a powerful black-box testing tool.
Black-box strategies naturally exist in some level of ambiguity; there is a large bit of information about the SUT that is missing: the implementation. As mentioned, this is desirable to focus the testing on the actual business requirements, but difficulty arises in needing to comprehend the full scope of those requirements. Different permutations of input or function or environmental states all need to be considered, so any tool that can help enumerate these states is desirable.
Different systems are naturally suited to different kinds of modeling, and while every system does have a control flow, it isn't necessarily the case that every system is best understood by a model of its control flow. Plenty of system are though, and in those cases CFWeaver will be a good fit.